
Pick-a-Pic: An Open Dataset of User Preferences for Text-to-Image Generation

Images generated via the Pick-a-Pic web app show darkened rejected images (left) and preferred images (right).
Introduction
Pick-a-Pic is a large and open dataset for human feedback in text-to-image generation. It was developed as a collective project led by Yuval Kirstain, Adam Poliak, and Omer Levy from Tel Aviv University, Uriel Singer from the Technion Institute of Technology, and Joe Penna and Shahbuland Matiana from Stability AI, with compute kindly granted from Stability AI.
In this blog post, we provide an overview of how we built the Pick-a-Pic dataset and how we leveraged this dataset to develop PickScore, a scoring function that exhibits superhuman capabilities in predicting human preferences. We also describe how we used PickScore to suggest an updated, more relevant protocol for evaluating text-to-image generation models, and how PickScore can be used to enhance text-to-image models.
Method
Aligning pretrained models with human preferences has been crucial in developing helpful models like InstructGPT and products like ChatGPT. However, the issue of aligning models with human preferences – manual feedback on the quality of an image produced – has received little attention in the field of text-to-image generation. This lack of attention can largely be attributed to the absence of a large and open dataset of human preferences over state-of-the-art image generation models. The goal of Pick-a-Pic is to unlock this barrier, by providing a dataset of over half-a-million examples of text-to-image prompts and real user preferences over generated images.
To build this dataset, we developed a web application (https://pickapic.io/) that allows users to generate images using state-of-the-art text-to-image generation models (including some exciting SDXL variants 😀) while specifying their preferences. With explicit consent from the users, we collected their prompts and preferences for this dataset, which consist of more than half a million examples. Each example in this dataset includes a prompt, two generated images, and a label indicating the preferred image, or a tie when no image is significantly preferred over the other. To provide a clear understanding of the web application, and the collected preferences, we have included a visualization of the web application’s user interface below.
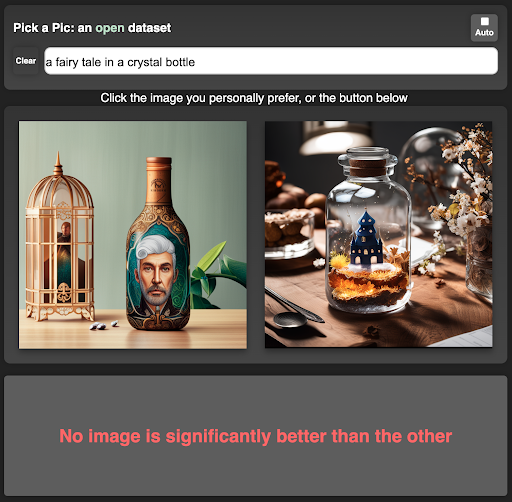
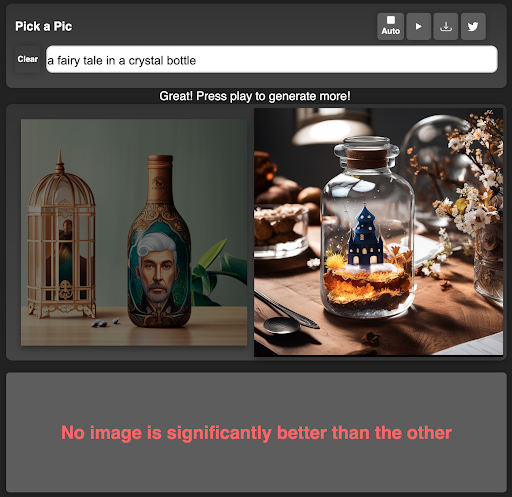
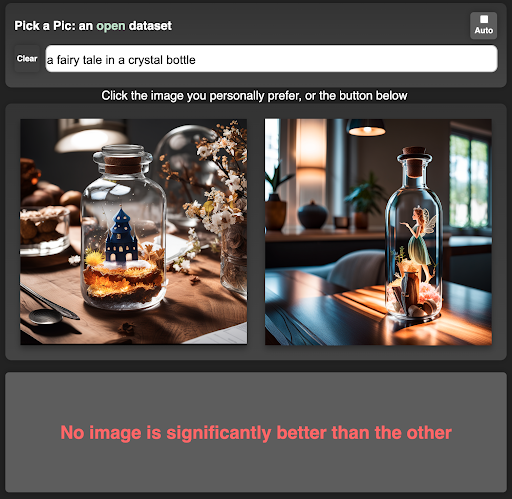
How Pick-a-Pic data is collected through the app: (1) the user first writes a caption and receives two images; (2) the user makes a preference judgment; (3) a new image is presented instead of the rejected image. This flow repeats itself until the user changes the prompt.
We then used this dataset to train a scoring function that estimates users' satisfaction with a generated image based on a given prompt. We achieved this by finetuning CLIP-H using an objective similar to InstructGPT's reward model. This objective aims to maximize the probability of a preferred image being chosen over an unpreferred one, or even the probability in cases of a tie. We found that the resulting scoring function, PickScore, achieves superhuman performance in predicting user preferences with an accuracy rate of 70.2%, compared to expert humans' 68.0%. In contrast, zero-shot CLIP-H and the popular aesthetics predictor perform much worse, closer to chance (at 60.8% and 56.8%, respectively).

Comparison between scoring functions on the Pick-a-Pic preference prediction test set.
Given a dataset of human preferences and a state-of-the-art scoring function, we suggested an updated protocol for evaluating text-to-image generation models. Firstly, we proposed that researchers evaluate their models using prompts from the Pick-a-Pic dataset, that more accurately reflect what humans want to generate. This is an improvement over mundane captions found in MS-COCO, which is the standard benchmark for evaluating text-to-image models. Secondly, to compare PickScore with FID, the main metric used when evaluating text-to-image models, we conducted a human evaluation study and found that even when evaluated against MS-COCO captions, PickScore exhibits a strong correlation with human preferences (0.917), while ranking with FID yields a negative correlation (-0.900). Furthermore, we also compared PickScore with other evaluation metrics using model rankings inferred from real user preferences. We observed that PickScore is more correlated with ground truth rankings, as determined by real users. Thus, we recommended using PickScore as a more reliable evaluation metric than existing ones.
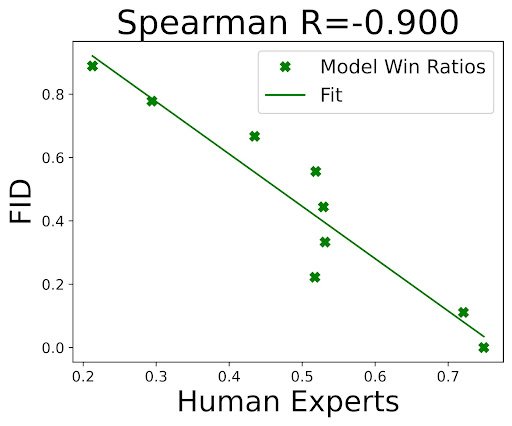
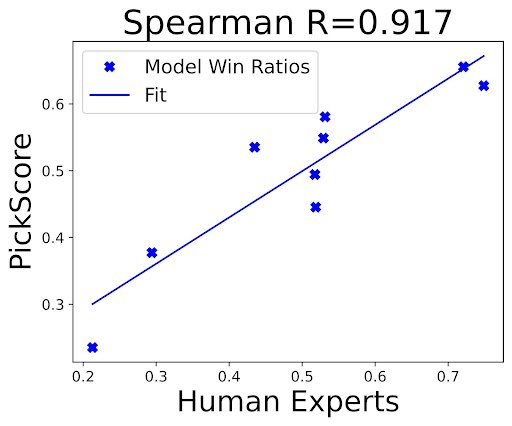
Correlation between the win ratio of different models according to FID and PickScore to human experts on the MS-COCO validation set.
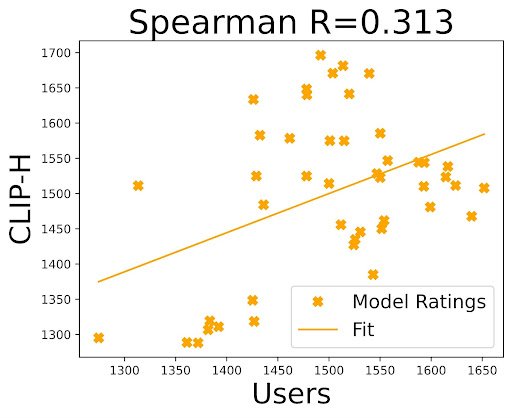
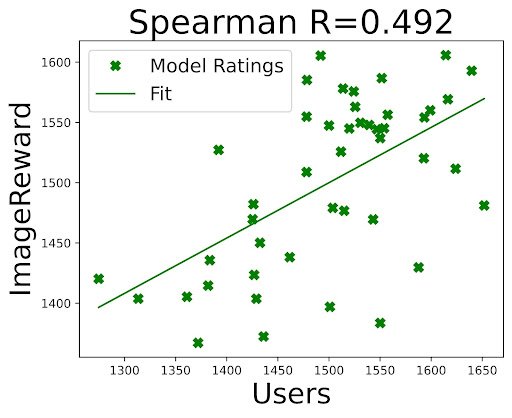
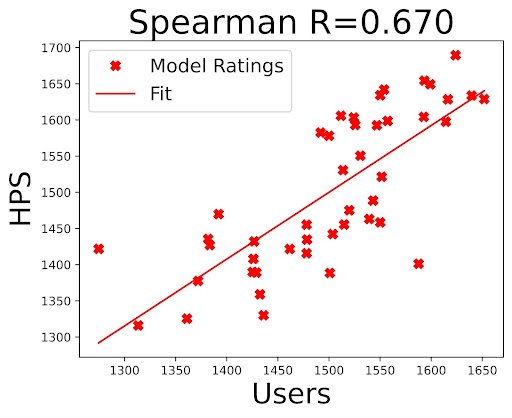
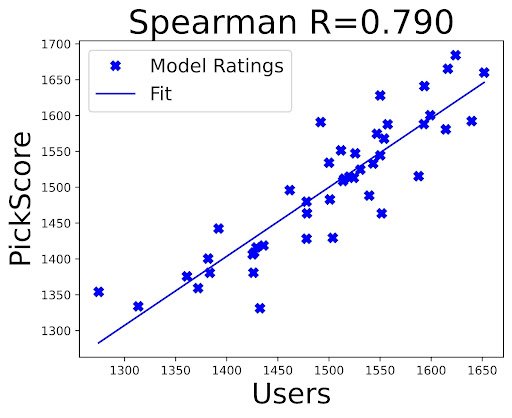
Correlation between Elo ratings of real users and Elo ratings by PickScore and other automatic metrics
In the final section of the paper, we explored how PickScore can improve the quality of vanilla text-to-image models via ranking. To accomplish this, we generated images with different initial random noises as well as different templates (e.g. “breathtaking [prompt]. award-winning, professional, highly detailed”) to slightly alter the user prompt. Then, we compared the impact of selecting the top image according to different scoring functions. The results show that human raters prefer images selected by PickScore more than those selected by CLIP-H (win rate of 71.3%), an aesthetics predictor (win rate of 85.1%), and the vanilla text-to-image model (win rate of 71.4%). We add a visualization from the paper on the difference between standard text-to-image generation (vanilla) and selecting the best image according to PickScore below.

Comparing the image from the vanilla text-to-image model (left) with the image selected by PickScore from a set of 100 generations (right).
Conclusion
The Pick-a-Pic dataset was created by collecting prompts, generated images, and user preferences from the Pick-a-Pic web application for text-to-image generation. The resulting dataset contains more than half-a-million examples and is available for public use. The quantity and quality of the data enabled us to train PickScore, a state-of-the-art text-image scoring function, which achieves superhuman performance when predicting user preferences. PickScore aligns better with human judgments than any other publicly-available automatic metric, and together with Pick-a-Pic’s natural distribution prompts, enables much more relevant text-to-image model evaluation than existing evaluation standards, such as FID over MS-COCO. Finally, we demonstrated the effectiveness of using PickScore for selecting images in improving the quality of text-to-image models. There are still many opportunities for building upon Pick-a-Pic and PickScore, such as RLHF and other alignment approaches, and we are excited to see how the research community will utilize this work in the near future.
We provide a link to the paper, the authors’ original tweet about the paper, and the GitHub repo for the project.